Adventures with Cloudfront 502s
The plan
Dealing with legacy code is never boring, especially if you want to change something fundamental in the app. We decided that it was time to detach the frontend application from the backend service. In the old setup we had a Django application responsible to serve the API endpoints + it served a static HTML page hosting the frontend application. Even though the separation wasn’t super straight forward as some variables were passed to the frontend via Django template tags, refactoring them to be consumed by webpack from a settings.json file went fairly smoothly. The troubles began when it was time to separate the infrastructure. Without going into too much detail, the backend service was and would still be sitting behind an application load balancer while the frontend app would be uploaded to an S3 bucket both sitting behind a Cloudfront distribution. Nothing too crazy.
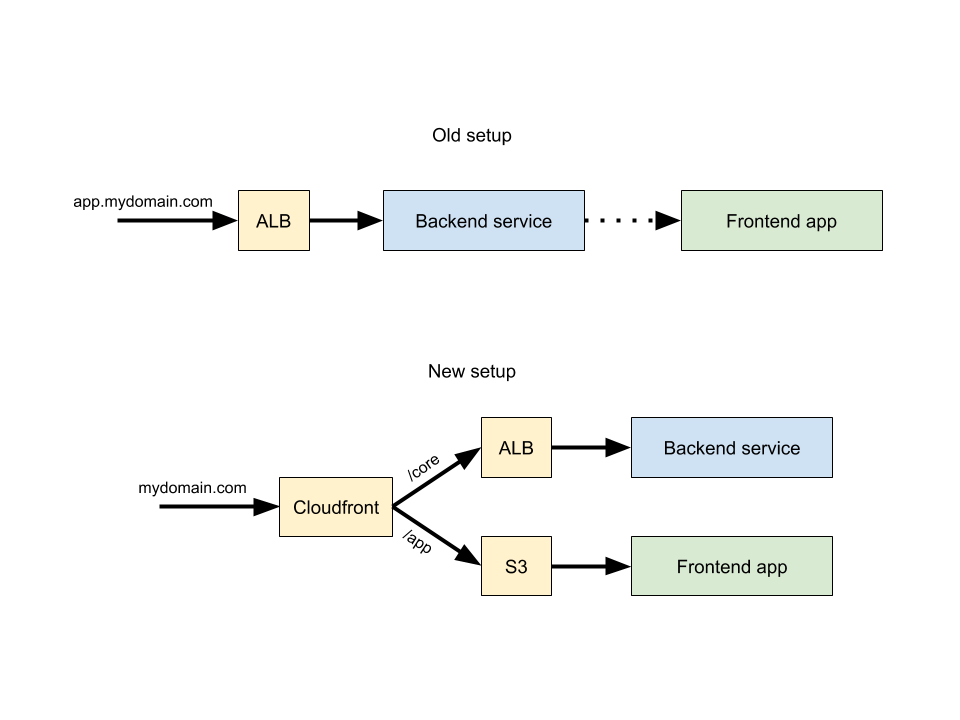
Domain changes
This also seemed to be a good time to update the website’s domain structure a little bit and get rid of the app.* subdomain. We have two QA, a staging environment and a production environment. The old domains were as follows:
qa1.mydomain.com(QA1)qa2.mydomain.com(QA2)app.staging.mydomain.com(staging)app.mydomain.com(production)
As you can see there was some incosistency across the environments whether to use the app subdomain or not, so at least this work would resolve this as well. The plan was to update the routing to use either /app path for the static frontend app (S3 bucket) or /core where the APIs would be attached (via an ALB). This would result in the following routes:
qa1.mydomain.com/appandqa1.mydomain.com/coreqa2.mydomain.com/appandqa2.mydomain.com/corestaging.mydomain.com/appandstaging.mydomain.com/coremydomain.com/appandmydomain.com/core
These updates will become relevant later.
QA, staging, production
Once the necessary code updates have been implemented, it was time to deploy to QA. The buckets were created and configured, a Cloudfront distribution was created with the two origins (S3 and ALB), SSL certificate was issued. The application was then deployed and after a few initial issues, everything was working great! After having the solution deployed to QA for a while, we got pretty confident about the solution, and we decided it was time to merge the code changes and deploy to staging. Once deployed, no hiccups whatsoever, everything was working smoothly straight away. At this time the buckets and Cloufront distributions have already been created as a preparation for both staging and production environment. It was then time to go live. We started the deployment process and once it was deployed, we switched our domains over to use the new cloudfront distribution instead of the load balancers…. Only to realise that all API endpoints are returning 502s.
502
Even though the frontend was loading perfectly and the login page was rendered without any issues, we immediately realised that users were not able to log in. Thankfully we timed this update outside core hours, so not many users were affected.
502 is the error message that can mean a lot of things, so using our years of engineering experience, we managed to Google the issue fairly quickly. There’s a troubleshooting page dedicated to Cloudfront’s 502 response with list of things that could go wrong, so we started going through the list.
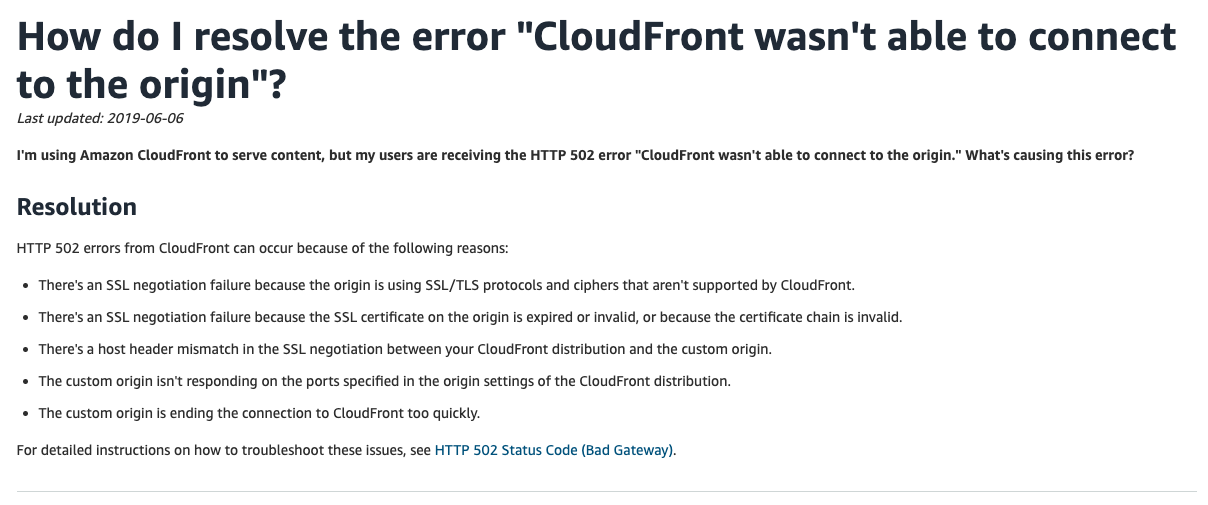
It was pretty clear that the issue is not with Cloudfront itself, but either something with the backend service or something between Cloudfront and our backend service. Some quick curl calls proved that the ALB is fine as it returned non-5xx responses. We then went through the origin and behaviour configuration for the backend service and all seemed to be correct too. We started to worry.
Domain changes part 2
Of course when we tried the curl calls, we just did a quick curl against the ALB DNS name provided by AWS. Which is by default http in curl, unless specified otherwise. In reality however, the Cloudfront origin was configured as https. After trying to curl via https (realising this is what the troubleshooting guide is trying to say), we finally managed to get an SSL error!

credit: https://www.reddit.com/r/me_irl/comments/86tb5k/meirl/
Invalid certificates? How could that be? We haven’t updated anything certificate related other than issuing new Cloudfront certificates which were working just fine. All ALBs were configured to use the same certificate with a wildcard *.mydomain.com. And there it was. *.mydomain.com was a perfectly valid wildcard for all the old domains, also for the new QA and staging domains. However, since we’ve changed the production domain from app.mydomain.com to mydomain.com/core, the wildcard did not apply to that domain anymore as there were no more subdomains.
Why was only the backend broken?
If you’ve ever configure Cloudfront with SSL managed by AWS, you know that the certificates for all distributions have to be issued in the “us-east-1” region. When the new distributions were created, we created a new certificate for all domains. However, for the load balancer certificates you have to issue them in the VPC’s own region. Even though we did update some configuration on the ALBs (set up 301s for the old domain, update target group rules, etc.), we’ve completely forgotten about the certificates attached to the HTTPS listener. Especially since everything was working perfectly on QA and staging, we wouldn’t have thought there could be issues on production. Basically since the ALB’s certificate was invalid, the issue only affected the connections towards the backend.
Takeaways
For me the biggest takeaway from this incident is that I should always double-triple check SSL certificates when moving domains around. It’s easy to take things for granted, especially if things seem to work fine on QA and staging, but I should always consider the differences between these environments and production and their possible consequences.
Also, error reporting with Cloudfront is not very great. I understand that this is kinda sensitive information and should not be revealed to visitors, however it would be great to somehow publish these error messages to Cloudwatch.